1. はじめに
日本語には「面白い」という単語があります。 辞書で意味を引いてみると次のような意味らしいです。
1 興味をそそられて、心が引かれるさま。興味深い。「何か―・いことはないか」「仕事が―・くなってきた」「この作品は―・くなかった」
2 つい笑いたくなるさま。こっけいだ。「この漫画はなんとも―・い」「―・くもない冗談」
3 心が晴れ晴れするさま。快く楽しい。「夏休みを―・く過ごした」「無視されたようで―・くなかった」
4 一風変わっている。普通と違っていてめずらしい。「―・い癖」「―・い声」
5 (多く、打消しの語を伴って用いる)思ったとおりである。好ましい。「結果が―・くない」
6 風流だ。趣が深い。
面白い(おもしろい)の意味 - goo国語辞書
が、なぜか僕が「面白い」という言葉を使うと、字義通りの意味で取っていただけません。
どやの面白いは多義語だからな
— リブロ (@Aware_Japan) August 1, 2020
どやの「面白い」は良い意味で面白いのときと悪い意味で面白いのときがあるからな
— とても上品 (@dedede467099) December 22, 2020
今回はどっちも悪い意味のはず
キレそう。
どうやら僕の使う「面白い」という単語には「原義面白い(順に面白い)」と「広義面白い(逆に面白い)」の2通りの解釈があるらしく、その意味は割と反対の意味合いを持っているようです。 古文単語かよ。
そこで、本記事ではニューラルネットワークの技術を用いることで、僕の発言の「面白い」が「原義面白い」と「広義面白い」のいずれにあたるのかを判別できるかを調査しました。
本記事の構成は以下のようになっています。
2章では関連研究に触れます。 3章では実際に行なった実験内容および実験結果をまとめます。 4章ではまとめを述べます。
2. 関連研究
ここでは、今回使用した技術を簡単にまとめます。 具体的に用いた技術に興味がない方は、3章まで飛ばしてくださっても構いません。
ニューラルネットワークと自然言語処理(NLP)
こういった自然言語を対象とした研究を自然言語処理(Natural Language Processing、NLP)と言います。 最近はニューラルネットワークを用いたものが多いですね。
NLP においては基本的には入力は文です。
が、このままだと扱いづらいので最終的に何かしらの数値で表してやりたいです。
まず、ここでは、文を単語(や文字)の時系列データとみなします。
つまり、sentence = I have a pen. みたいな文があったときに、こいつを sentence = [I, have, a, pen, .] みたいな配列とみなすわけです。
で、このままこのデータを扱うのは難しいので、単語を何かしらの計算可能な数値に変換します。
たとえば、単語の id みたいなものを用意してそれをそのまま割り振るとかが直感的ですね。
sentence = [233, 255, 17, 18, 3] みたいな。
こうして、文を数値として扱うことができるようになりました(めでたしめでたし)。
実際には少しだけ違くて、各単語をスカラー値ではなくベクトル値で表現したりするのですが、それはまた別のお話ということで。
ニューラルネットワークは言ってしまえば、数値(ベクトル)を受け取って数値(ベクトル)を返す関数なので、数値化した文はニューラルネットワークで扱えるわけですね。
パーセプトロン
すごいシンプルなニューラルネットワークです。 ベクトルを入力して、0〜1の値を出すだけ。 2値分類が解けますね。
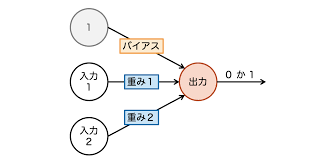
これを横並びにすれば、多クラス分類もできます(それぞれの0〜1がそれぞれのクラスの推論値に相当する)。
BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin et al., 2019.
パーセプトロンの次にこれ来るのマジ?
NLP 界隈で直近5年の最もすごい論文5本挙げろと言われたら、まず入ってくる論文です *1。 ここで提案された BERT というモデル(手法)がえげつなくて、これ以前と以後で世界観が変わります。 このモデルは色んなタスクに適用できるので、大抵のタスクの SoTA はだいたいこれとこれの派生系が使われています。 とんでもないですね。
ざっくり説明すると、 Transformer という最近出てきたつよつよモデルに、大量(マジで大量)のデータを食わせて事前知識を学習させるという手法です。 大量の事前知識を持った BERT を特定の解きたいタスクに微調整(Finetune)することで、事前知識のおかげでめっちゃ良い性能が出るというコンセプトになっています。
NLP 界隈のガブリアス(ポケモン第4世代)、デュアルスイーパー(Splatoon2)、メタナイト(スマブラX)みたいなものです。
3. 提案手法
データセット
まず、学習を回すためのデータセットを用意しました。
データは僕の twitter アカウント(@hilinker)の全ツイートの中で、「面白い」「面白すぎ」のいずれかが含まれるツイートを抽出しました。 結果、全体で 998 ツイートを得られました。
次に、ツイートに含まれる「面白い」が原義なのか広義なのかを人手でラベル付けしました。 おそらくこのタスクが地球上で最も上手いのが僕なのですが、それでもなお難したったです。 一応、1つ基準として定めていたのが「逆張り界隈に身を置いていない人間に対しても真顔で面白いと言えるか」です。 そして、考えても分からないものは原義であるとラベル付けしました。 そもそも、「面白い」には原義しかないはずなので。
結果として、998 のデータ中、原義面白いが 755 で、広義面白いが 243 となりました。 全体の 75% ぐらいが原義ですね。 当たり前なんだよな。オレが逆張りばっかりしてる人間だと思ってる人間どもは反省しろ。
さて、いくつか例を引っ張ってきました。
原義面白い
- クソアニメばかり見ていると思われがちだが、これは偽で面白いアニメも見ているんだよな。
- 今期、サクラダリセット、アポクリファ、レクリとくっそ面白いアニメ勢ぞろいだしマジで豊作。
- ウマ娘、真面目にスポ魂やってて面白い。
広義面白い
- 百錬覇王、全てがチープでマジで面白い。
- 「私なら、誰も殺さない戦い方ができる!」とか言った直後に敵軍に雷放つの面白すぎるだろ。
- 国会答弁、虚無過ぎて面白いよね。
まあ、なんとなく雰囲気は伝わったかなと思います。
実験1
以下の3つの手法で検証と比較を行いました。
- 全て原義とみなす
- 多クラスパーセプトロンの学習
- BERT の学習
1はベースラインですね。原義の割合が 75% なので、全部原義だと推論しても 75% ぐらいは正解してしまいます。これを超えられるかが肝ですね。 2は普通にパーセプトロンを学習しました。 3は事前学習済みの日本語 BERT を Finetune することで分類を行いました。
今回、データセットを訓練用データ 770、検証用データ 128 に分割して、検証用データの accuracy を比較しました。 本来は、検証用データとは別にテスト用データを用意しなくてはいけないのですが、データ数が少ないのと面倒くさいので検証用データで一番よかったものを比較しています。
損失関数には CrossEntropy を用いました。バッチサイズは 8 にして、全部 20 エポック回しました。
実験結果
- 全て原義とみなす: accuracy = 0.78125
- パーセプトロン:accuracy = 0.78125
- BERT:accuracy = 0.78125
って、全部一緒やないかーい!!w
これ、何が起きてるかと言うと、パーセプトロンも BERT も学習を一定以上回すと「うーん、全部原義!w」ってところに落ち着いちゃうんですよね。 だいたい1エポック回し終える頃にはすでにこの局所解に陥ってしまいます。
学習率を 0.1〜0.001 の範囲で変えたり、Dropout などの正則化を入れたりしたんですけど、すぐに全部原義であると推論してしまいます。
こうなる原因としてはいくつか考えられます。
- 訓練用データ中で、広義より原義の方が圧倒的に多いのでそこに落ち着いてしまう。
- そもそもデータ数が少なく、原義・広義のニュアンスを学習できるほどの十分なデータ数がない。
- ツイート単体では判別不可なタスク。
1つ目については簡単に解決できそうなので、次の実験を行いました。
実験2
実験1で、訓練データ中の偏りが悪いのでは?と思い、再度実験を行いました。 ここでは、訓練データに含まれる原義面白いデータを間引いて、原義と広義のデータ数が同じになるようにしました。 ちなみに検証用データについては何も変えていません。
- 全て原義とみなす: accuracy = 0.78125
- パーセプトロン:accuracy = 0.78125
- BERT:accuracy = 0.78125
半々にしても、張り付いてしまいました。 ただ、BERT の方は結構学習が不安定になったというか、エポックごとに検証用データの accuracy がかなりブレました。 だいたい、0.2〜0.78125 の間でブレていて、半々にするとより学習がうまく行っていないなぁという感じです。
4. まとめ
今回、「原義面白い」と「広義面白い」をニューラルネットワークが判別できるのかを検証しました。
実験結果としては、全部原義であると推論するようになってしまい、判別はできなかったという結果になりました。 BERT でさえ、広義面白いという概念を理解できていなさそうです。当たり前なんだよな。なんだよ、広義面白いって。
原因としては、上でも書きましたが以下のようなものが挙げられますね。
- そもそもデータ数が少なく、原義・広義のニュアンスを学習できるほどの十分なデータ数がない。
- ツイート単体では判別不可なタスクである。僕はコンテキストを理解しているのでラベル付けできたけど、普通に渋谷の街角とかで赤の他人にラベル付けさせたら無理なのでは。
これを踏まえて、今後の課題としては以下のようなものが考えられます。
- BERT の学習時に僕の他のツイートをモデルに事前に入れて、コンテキストの学習をさせる。
- 僕が、積極的に広義「面白い」を含むツイートをしてデータ数を増やす。
- 他の人の「面白い」を含むツイートも学習に加える。
- 渋谷の街角で順張り健常者に正解ラベルのアノテーションをさせる。
他にももう少しヒューリスティクスを入れることも考えてもいいかもしれません。 たとえば、「虚無」がツイートに含まれていたら広義とか、「真面目に」が含まれていたら原義とか。
結論
大量の SoTA を叩き出した BERT ですら、「うーん、全部原義!w」って言ってくれてるんだし、僕の「面白い」は全部原義なのでは????
*1:あと4つ選ぶの大変だけど、うち1つは流石に「Attention is all you need」かなぁ。